
A CI/CD architecture or infrastructure helps development teams to deliver software. Of course a manual and local build and deploy from the command line is always possible. But sooner or later a more sophisticated setup is beneficial. More sophistication means here that more steps in the whole CI/CD pipeline are automated or steps are added to the pipeline or somehow extended. CI/CD setups come in many different shapes and forms. In this article we take an abstract view on them and build them from simple to more sophisticated in an incremental way.
Please note that CD in this article summarises continuous delivery as well as continuous deployment.
#1 The most basic setup with local build and deployment
We start simple with local source code where the build task is executed also locally by the required build system. Locally here means on the developers machine. After having built the software artefact the deployment also happens from local by uploading the artefact onto the application run environment. Finally the application is restarted.
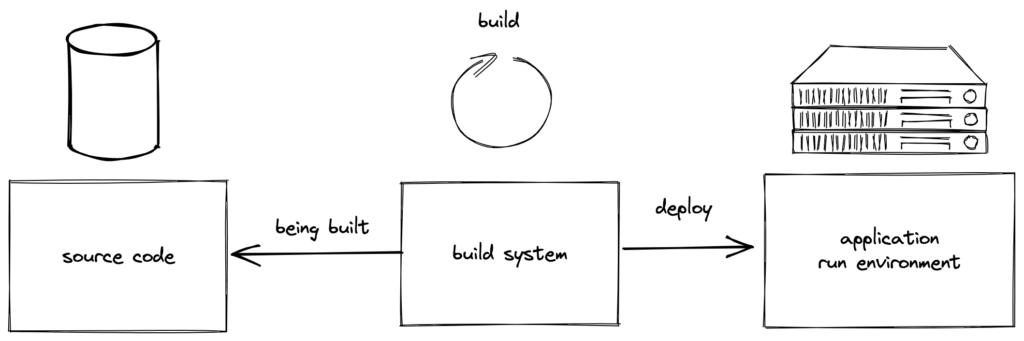
#2 Code repository and build server added
In a first step we add two systems into our infrastructure. This allows us to automate and outsource some tasks:
- The source code is no longer kept only locally but is stored in a distributed source code repository.
- The build task is not executed anymore locally but on a build server. Also the deployment is done by the build server. The build server is just another machine and ideally optimised for building software.
- A connection is setup between the source code repository and the build server. This allows us to retrieve the source code.
Once we trigger the build (manually) on the build server the source code is loaded and the build tasks are executed on that code. After the build is done the created artefact is moved onto the application run environment where a restart happens. The new version is available.
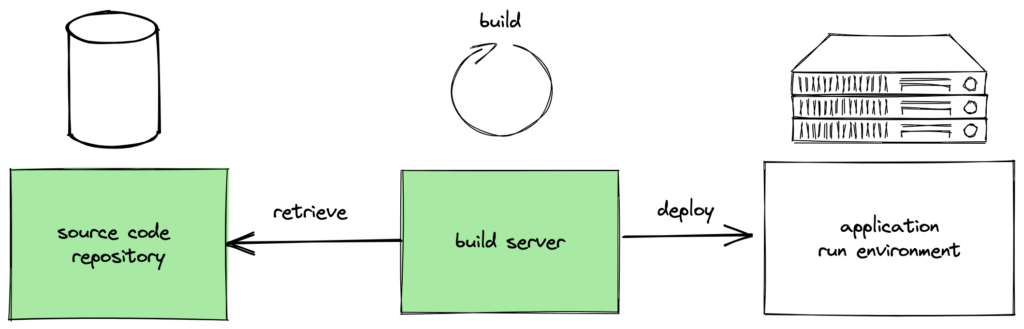
In above variant no developer’s machine is involved anymore. Of course developers push the code into the distributed source code repository, but for the CI/CD flow itself the work is outsourced.
Outsourcing the build task helps to keep the developer’s machine free for other tasks. Additionally there is an independence introduced such that the build can be started at any point in time.
#3 Notification about new source code for the build server
In a next variant we bring in some automation. We setup a second connection between code repository and build server to notify the build server about a new code state. So, whenever a new state is ready to be built the build server will automatically trigger a build.
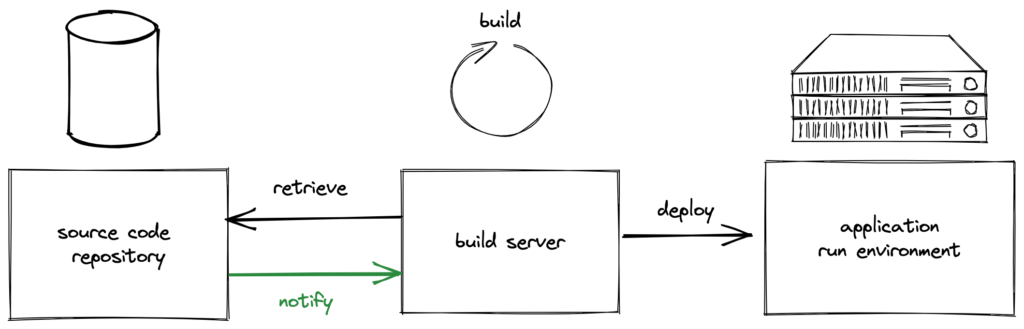
This allows us to get rid of the manual trigger for the build. Hence, forgetting to trigger the build is not an issue anymore.
Still the deploy task is automatically executed at the end of the build and a new application version is available soon after a build.
#4 Separate build and deployment
Until now a new build always meant a new deployment. Hence, there was really Continuous Deployment. A new artefact was built directly on the build server, kept there temporarily and put onto the application run environment. Now we separate the build from the deployment:
- An artifactory is introduced as additional system into our CI/CD architecture. The function of this artifactory is primarily to store software artefacts and allow a later retrieval, also repeatedly.
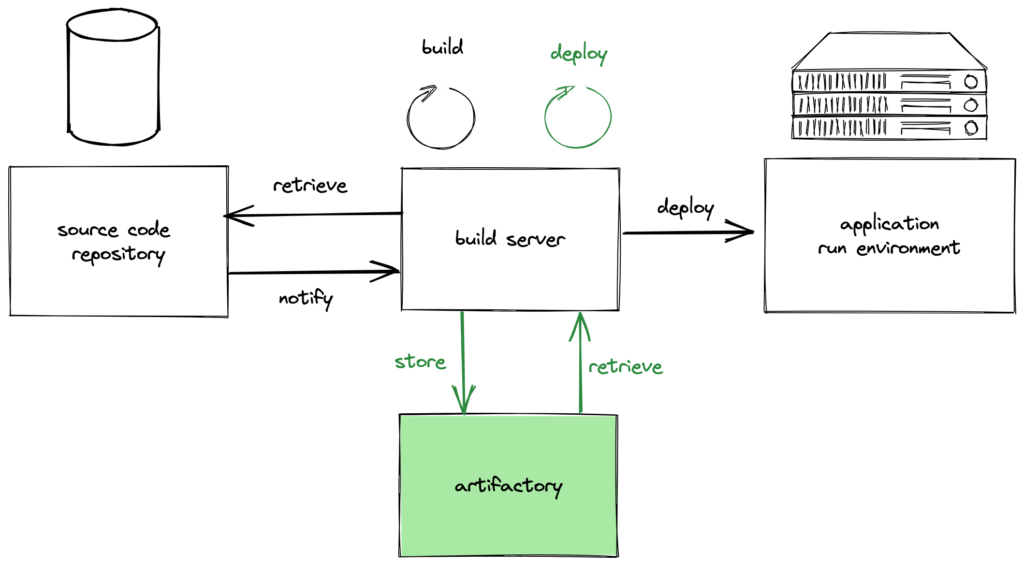
This brings us the following advantages:
- Build and deploy step can be separated also in time. The build step stores the artefact and some time later the deploy step can retrieve the artefact independently of the build step.
- Build and deploy step could be separated physically. Infrastructure that is optimised for the build task can be used entirely for the build. While the deploy step can again be on a separated physical infrastructure. This deploy infrastructure could then exclusively have access to the application’s run environment improving security.
- Artefacts are not lost after deployment but stored for a certain amount of time. This allows also a later retrieval, e.g. for another deployment or rollbacks.
Integrating code, building the software and storing into the artifactory is basically Continuous Delivery. When we connect these steps with the deployment we have Continuous Deployment.
#5 More quality checks
We want to ensure a certain standard whenever we integrate new code or at least before delivering or deploying new software artefacts.
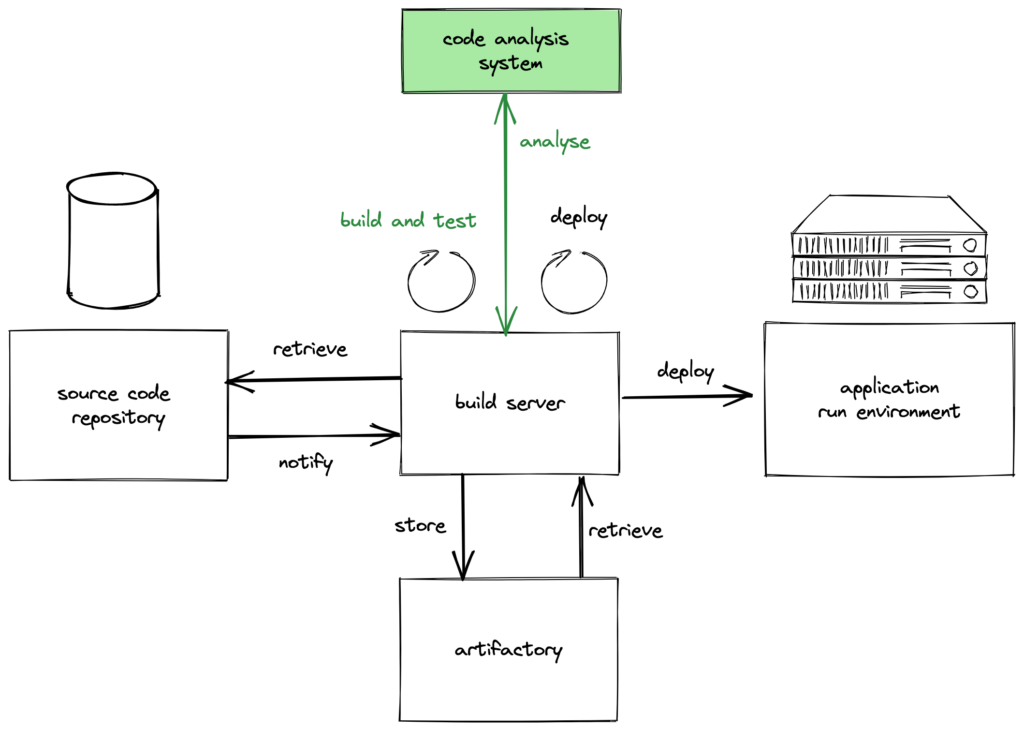
To check the quality of our software artefacts the CI/CD architecture is extended by the following:
- The software is not only built but also tested by executing automated tests during the build. Whenever tests fail the build fails too and no new artefact is created.
- In addition to basic checks, further code analysis tools can be integrated into or directly after the build step. External code analysis systems give the build server feedback about the code or the artefact. This feedback can concern for example code quality, but also security. Also a negative result here will fail the build and prevent shipping software that doesn’t adhere to defined standards.
#6 Deployment could equal artefact retrieval
What if the deployment is not triggered from the build server and the artefact is not pushed towards the application run environment? There certainly exist such cases where it is rather a pull form the run environment, e.g. mobile app download onto the device via app store. Then our CI/CD architecture view needs to be extended:
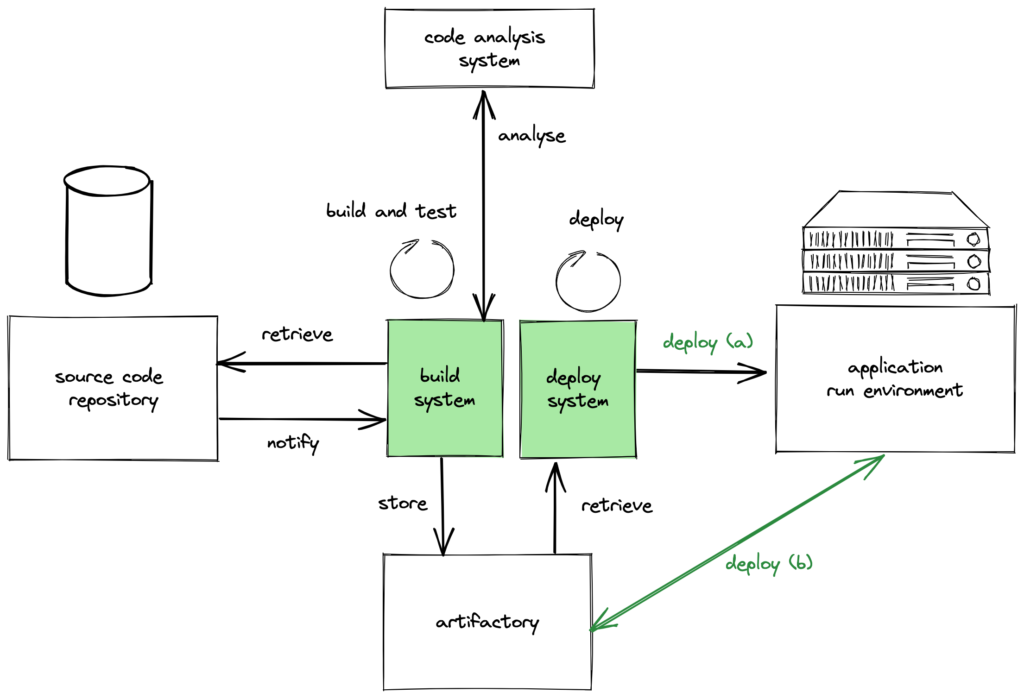
The following changes were applied:
- We definitely separated the build and deploy and renamed them to build system and deploy system.
- There are two variants for deployments shown:
- Either it is a push deployment from the deploy system that puts the artefact onto the application run environment -> deploy (a)
- Or it is a kind of pull deployment where the run environment pulls the artefact directly from the artifactory -> deploy (b). In this case no deploy system is needed. Or you could say that the deploy system is actually running on the application run environment.
#7 Deployment without interruption
Until now the deployment was just about putting a new version onto the run environment and restarting. This usually causes an interruption for the user of our software. We can do better than that!
- During deployment a second instance or set of instances of the application run environment is created where the new version is installed.
- A router is part of the run environment or sits in front of it. This router controls the access of the users to the right version of the application.
- After deployment the end-users are routed to the instance(s) with the new version and the old version’s instances are removed.
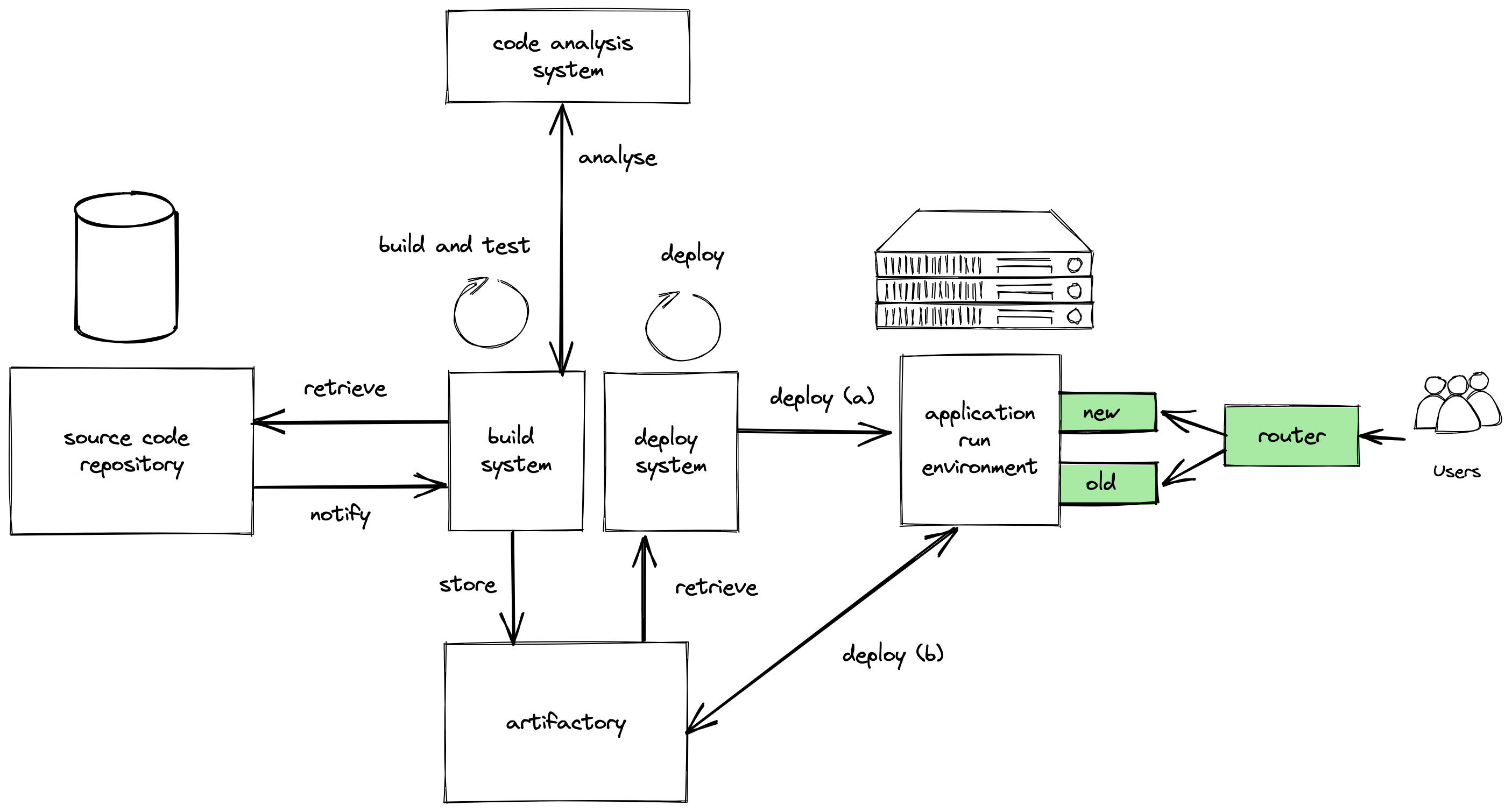
Continuous deployment ideally means that a deployment can happen anytime without the users really noticing. The users should only see the new features or the fixed bugs. This is achieved by above extensions.
#8 Deploy with quality check
It is time for a bit more quality again. We already have the tests that are run during the build and the additional code analysis done after that. Now we will introduce an incremental rollout (canary deployment).
- Like in #7 a second instance or set of instances is used during deployment
- This time the router is a bit more intelligent and routes a certain subset of users towards the new version of the application.
- A monitoring system is introduced that allows us to check the quality of the new version. The deploy system has access to this monitoring system to check the quality metrics regularly and proceed or abort with deployment.
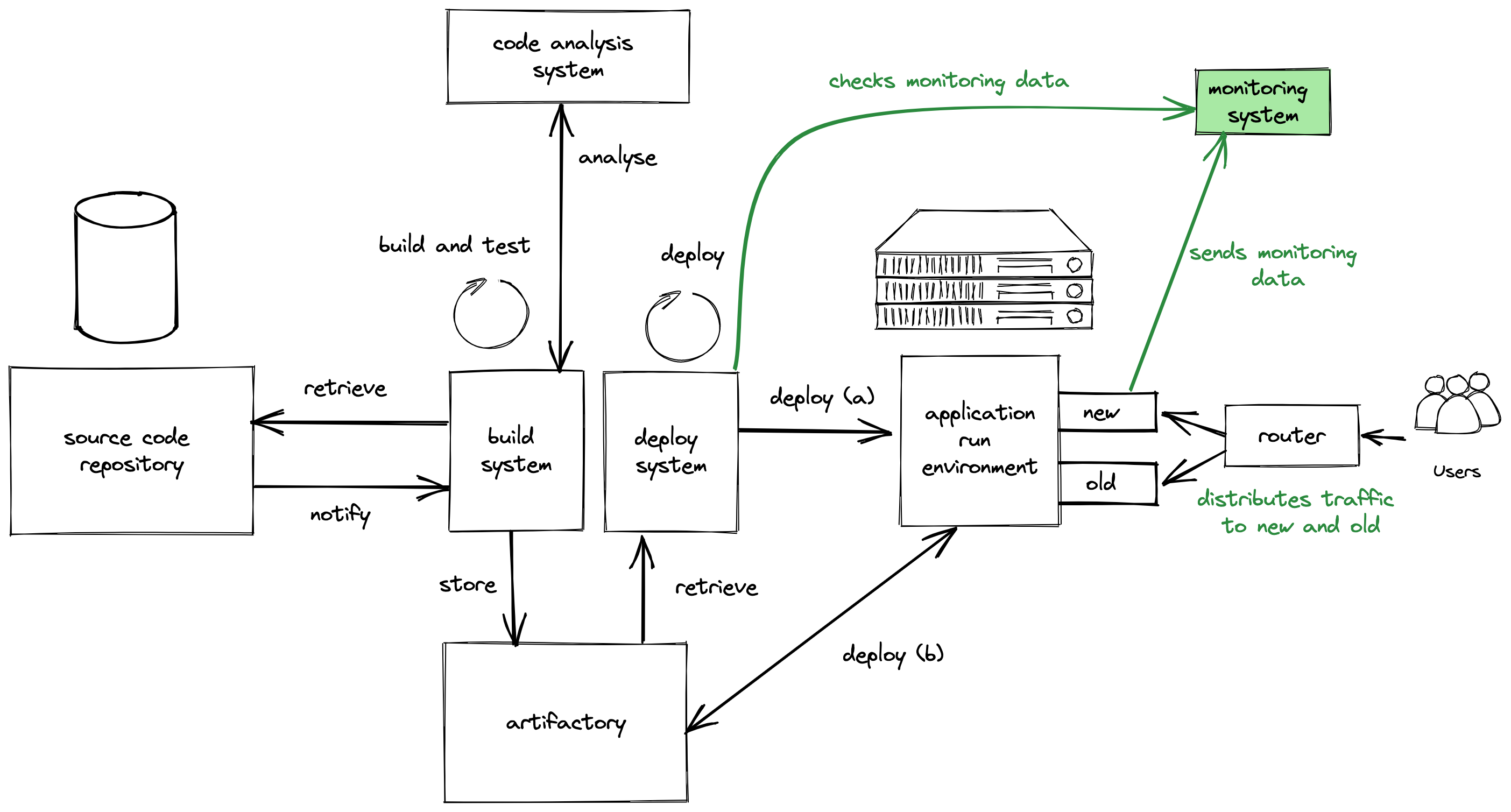
This allows us to only send a subset of users onto the new version of our application in the beginning of the deployment. Once the quality checks are giving us good feedback we can increase the amount of users routed to the new instance(s). When our monitoring system detects issues on the new version the deployment can be automatically cancelled. Luckily only a subset of users where then affected by problems and not everyone.
#9 We want to know what is happening
Above CI/CD setup already looks quite good. But we want to know during the whole process if certain steps fail or maybe also when everything went fine. This is why a notification system is introduced that can interact with various communication channels. Notifications can be triggered from several systems in the setup:
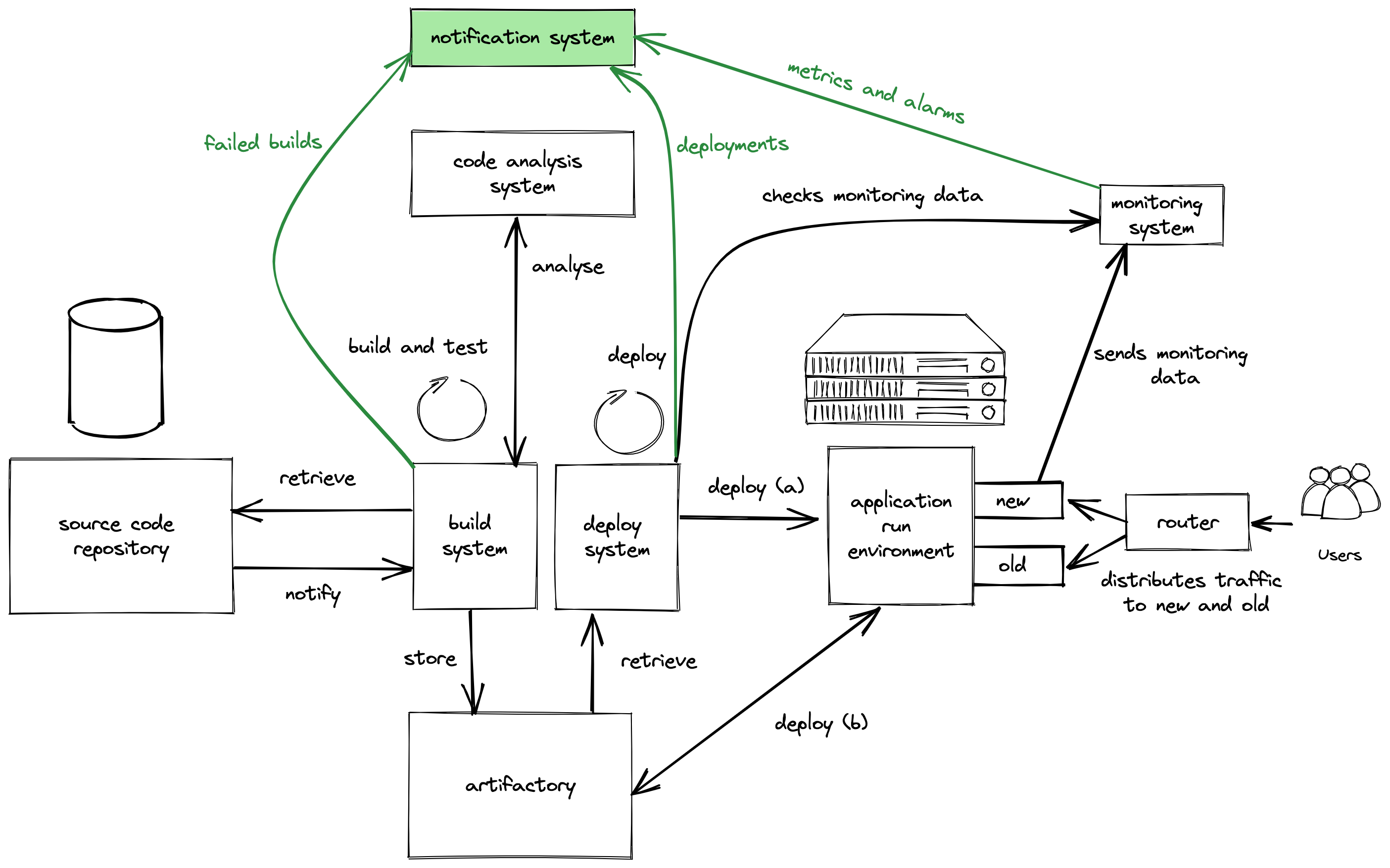
This is it for now! In 9 steps we have constructed an abstract view for CI/CD infrastructures. Further systems could be added of course, for example:
- user management integration to control which users have access to which systems and to provide SSO
- integrations with systems that publish release notes, API updates, etc.
- to further improve security we could scan the artifactory regularly to detect vulnerable artefacts or dependencies
Quality aspects of a CI/CD architecture and infrastructure
Above you have seen different variants on how to achieve CI and CD. Like every other architecture also this CI/CD architecture has some quality aspects you should pay attention to. To name a few:
- Physical characteristics of each system and their influence on throughput, speed, storage, etc. Connected to that the scalability of the single parts and the whole system.
- Security aspects for the connections between the systems
- Extensibility of the setup and adaptability to other scenarios, run environments, deploy paradigms, etc.
- Recoverability during the process to ensure that a step can be restarted rather than having to start the whole process again
Final thoughts
Probably you have not agreed with every detail of this CI/CD architecture or infrastructure. And this is okay. There are so many ways on how to setup such an architecture. Importantly is to understand your or your organisation’s needs and do the right trade offs. By keeping above elements and connections abstract we can discuss the architecture independently of tools and implementation details.
This gives us later on the flexibility to implement it with our favourite tools. Only then Jenkins, TeamCity, AWS CodePipeline and co. come into play.
